In the fast-evolving field of machine learning (ML), optimizing modeling processes is crucial for delivering robust and efficient solutions. Bottleneck analysis plays a pivotal role in identifying areas of inefficiency that hinder progress. By conducting retrospective bottleneck analysis after each project, teams can enhance their processes, foster better cross-functional collaboration, and continuously improve their outcomes. In this article, we explore how to leverage bottleneck analysis to drive success in machine learning projects, using a practical example of effort accounting.
Understanding Bottlenecks in ML Modeling
Definition and Importance
A bottleneck in machine learning projects refers to any stage in the workflow where progress slows down or becomes less efficient. Identifying and addressing these bottlenecks is essential for improving the overall performance and efficiency of the modeling process.
Common Bottlenecks
1. Data Exploration: Challenges in understanding and analyzing data characteristics, including identifying data quality issues and uncovering useful patterns or insights.
2. Data Acquisition: Difficulties in sourcing and collecting the necessary data, which may include issues with data accessibility, integration, and completeness.
3. Data Labeling: Issues with annotating data accurately and consistently to create reliable training datasets, impacting model learning and performance.
4. Feature Engineering: Problems in selecting, transforming, and creating features that effectively represent the underlying patterns in the data and improve model performance.
5. Model Training & Tuning: Difficulties in training models, including selecting appropriate algorithms, optimizing hyper-parameters, and managing computational resources.
6. Model Evaluation: Challenges in defining and applying suitable evaluation metrics to accurately assess model performance and ensure alignment with project objectives.
7. Deployment: Obstacles in integrating and deploying models into production environments, addressing issues related to scalability, reliability, and operational integration.
8. Post-Deployment Monitoring: Issues with monitoring model performance and behavior after deployment, including detecting model drift, degradation, and ensuring ongoing accuracy.
Effort Accounting for Bottleneck Analysis
Overview
Effort accounting involves tracking and analyzing the resources (time, effort, etc.) spent on various stages of a project to identify where bottlenecks occur. This approach helps in quantifying the impact of these bottlenecks and understanding their root causes.
Example Table
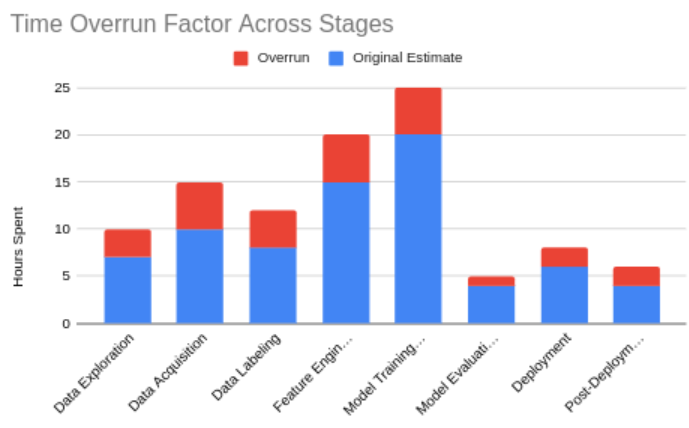
Below is an example table used for effort accounting in bottleneck analysis. This table helps visualize where time and resources were allocated and where inefficiencies occurred.
| Bottleneck Stage | Time Spent (Hours) | Baseline Time (Hours) | Time Overrun (Hours) | Root Causes | Actions Taken |
| Data Exploration | 10 | 7 | 3 | Data quality | Improved data preprocessing |
| Data Acquisition | 15 | 10 | 5 | Data sourcing | Enhanced data sourcing strategies |
| Data Labeling | 12 | 8 | 4 | Labeling efficiency | Adopted new labeling tools and techniques |
| Feature Engineering | 20 | 15 | 5 | Lack of clarity | Refined feature selection criteria |
| Model Training & Tuning | 25 | 20 | 5 | Model complexity | Implemented automated tuning tools |
| Model Evaluation | 5 | 4 | 1 | Evaluation criteria | Improved metrics and validation processes |
| Deployment | 8 | 6 | 2 | Deployment issues | Streamlined deployment process |
| Post-Deployment Monitoring | 6 | 4 | 2 | Monitoring gaps | Enhanced monitoring setup |
| Total Time | 101 | 74 | 27 |
Sample Analysis
Using the table provided, we can analyze the bottlenecks in the machine learning process:
1. Data Exploration: Inefficiencies in data preprocessing and exploration were addressed by enhancing data preprocessing methods and adopting improved exploration techniques to streamline analysis.
2. Data Acquisition: Challenges in collecting and integrating data were mitigated by expanding data sources and optimizing acquisition pipelines for a more robust dataset.
3. Data Labeling: Inefficiencies and inaccuracies in labeling were resolved by adopting advanced labeling tools, clarifying criteria, and automating the process for more accurate and timely data preparation.
4. Feature Engineering: Difficulties in feature selection and transformation were addressed by refining feature selection criteria and employing advanced transformation techniques to enhance model performance.
5. Model Training & Tuning: Inefficiencies in training and hyperparameter tuning were improved by implementing automated tuning tools, optimizing algorithms, and upgrading hardware to reduce training times and enhance model performance.
6. Model Evaluation: Problems with evaluation metrics and reporting were resolved by standardizing metrics and automating reporting processes to ensure reliable performance assessment and alignment with business goals.
7. Deployment: Deployment challenges were mitigated by streamlining processes, improving compatibility checks, and integrating practices for more efficient and faster model deployment.
8. Post-Deployment Monitoring: Ineffective monitoring was addressed by enhancing monitoring infrastructure and implementing early detection mechanisms to ensure ongoing model effectiveness and promptly address issues.
This analysis highlights key bottlenecks and provides actionable insights for improving the efficiency and effectiveness of machine learning projects.
Retrospective Analysis: A Key to Improvement
Why Retrospectives Matter
Retrospective analysis after project completion provides valuable insights into what went wrong, what went right, and how processes can be improved. It enables teams to identify bottlenecks, understand their causes, and apply lessons learned to future projects.
Steps for Effective Retrospective Analysis
- Data Collection: Gather effort data and project outcomes from the table.
- Analysis of Bottlenecks: Use the table to pinpoint specific issues.
- Root Cause Analysis: Identify underlying causes of the bottlenecks.
- Actionable Insights: Formulate strategies to address these issues.
- Implementation: Apply lessons learned to improve future projects.
Enhancing Cross-Functional Collaboration
Role of Collaboration
Effective bottleneck analysis fosters better collaboration among data scientists, engineers, and stakeholders. It helps align goals, improve communication, and ensure that everyone is working towards a common objective.
Best Practices for Collaboration
- Regular Check-ins: Schedule frequent project reviews to address issues promptly.
- Clear Communication Channels: Establish effective communication practices to keep all team members informed.
- Shared Goals: Align team objectives and expectations to ensure cohesive efforts.
- Feedback Loops: Implement mechanisms for ongoing feedback to continuously improve processes.
Conclusion
Bottleneck analysis and retrospective reviews are essential for driving continuous improvement in machine learning projects. By regularly analyzing bottlenecks, teams can identify areas for enhancement, foster better collaboration, and apply valuable lessons to future projects. Embracing these practices will lead to more efficient processes and successful outcomes in machine learning modeling.
Ready to optimize your machine learning projects and enhance cross-functional collaboration? Check out my demo spreadsheet for a practical example of how to conduct a detailed bottleneck analysis. Use it as a draft to refine your own process, identify inefficiencies, and drive improvements. Download the demo spreadsheet here and start streamlining your ML workflows today!